Statement on Stable Diffusion

To the Large Language Model and Multimodal AI community, today, I want to clear up the events that unfolded a week or two ago. These events were in regards to my dealings with the Stable Diffusion community. Although the weights for the model have already been leaked, making it almost pointless to continue discussing this, I think it is important to share my position, my side of the story, and clear up any misconceptions.
Two weeks ago, I tweeted the following:
Followed by this:
My goal here was to discourage the immediate public release of the weights which make up the model known as Stable Diffusion. I wasn't against releasing the weights completely, I was just against releasing them so soon.
At the time I tweeted this, I was concerned because I had attended the stable diffusion phase 3 (I believe) launch event just a week or two before. At the event, Emad (the founder of Stability AI) was saying that they were nearly done the training of Stable Diffusion (and planning to release its weights/code eventually under the apache/MIT licenses). Just a week later, there was serious talk of releasing the model itself, which I had found concerning because only a week or so had gone by … it had just been trained. This was when I had made those tweets.
Throughout the various stages of Stable Diffusion, I have received DM’s and calls from people who were concerned by the offensive and horrific content they were seeing on the Stable Diffusion official discord server. Photos of violently beaten asian women were the kinds of images people were originally generating on Stable Diffusion at a frequent scale (this is even knowing these results would be public for all to see and associated with their discord usernames permanently). Many of these people have told me, they are still disturbed by what they saw. Eventually, I believe with the help from moderators, SD had cleaned up most of the disturbing or unethical images they were seeing, however, I was now getting additional messages about the inherent biases in the model. Someone sent me a screenshot where they had simply entered the monkey emoji into Stable Diffusion and got back photos of black children. Was there any work at all put into bias before releasing this model to the public?
I have to admit that I found it peculiar - in the few weeks of its existence, the stable diffusion community was rampant with offensive, disturbing, and/or horrific content and devolving quickly. It was simply too toxic, and without the help from their volunteer moderators, they perhaps would have never recovered. Emad eventually actively discouraged NSFW content inside their discord server and I believe the community had made written strides against generating racist/offensive content. However, I just don’t understand, if it was too toxic, illegal, and/or dangerous to have on their own turf without heavy active human moderation, why were they releasing this model right away onto the whole world’s front yard?
In fact, Emad seemed OK with the model generating offensive content, at times encouraging it, just not on his own lawn (ie. discord server/Stability AI’s Commercial Product Dream Studio):


I believe a SD “community” twitter account even made encouraging indirect, “winks” like this as well. Not just to people in favour of nudity, but perhaps, to the much darker forces on the internet:

NSFW is a very, very, broad label - are violent/abusive images included under this label as well? Was Emad technically endorsing this, but just on everyone else’s GPU’s?
By my understanding, the model is capable of generating illegal child abuse images as well. Is this also encouraged by their organization under the NSFW label? At times, I see that Emad is discouraging this publicly on their discord and the licensing terms do not allow for illegal content, however, by releasing the model his actions say a lot too, so I just don’t know what to think:

To be clear, ethical concerns aside, I like a lot of the product features that Stable Diffusion is proposing:
fine tuning
speed
seeding
potential API
partnerships with other Creative AI startups
access for everyone
unlimited usage (on their own GPU)
community first, artist first culture
Ecosystem of tools being built on top of stable diffusion
upcoming features/modalities in the works
Model size - can run on most consumer GPU’s
How does it compare to OpenAI’s DALL-E 2? In my opinion, DALL-E is still the better model, especially for photo realistic generations. However, for digital art and other kinds of illustrations, I would say Stable Diffusion is pretty good and decently competitive with OpenAI.
They’re also engaging with the community (even me!) at a level and making moves at a rate the industry has never seen before. One specific thing I want to commend SD for doing is hiring and recruiting a lot of the key AI artists who I do feel were neglected, perhaps, by big players in the space despite their key contributions.
I have given props to SD for this kind of stuff in the past:
To be clear, now that the weights are released, I think Stable Diffusion may very well become the most widely used multimodal AI model in the world for the time being. And I’ve already said this publicly. I just don’t think, with the the way the weights were released, this is necessarily a broadly safe and healthy thing. We may be dealing with the toxic effects of this leaked model even a decade from now!
What are the Risks of Multimodal AI text2image models like Stable Diffusion?
There are numerous categories of risk for text2image models, including but not limited to:

I personally believe there are three other risky characteristics of text2image models:
Non Consensual
Most people nowadays interact with images through their social media feed, private group conversations, or chat servers. Even if they are not the ones behind the keyboard creating a horrific AI image, they may unfortunately come across an image generated by other actors on their social media unwillingly. This kind of mandatory AI image “opt in” culture is deeply unfair and problematic.Images have a deeper effect
Have you ever wished you could, “unsee” something? I just think images impact us at a deeper level subconsciously compared to other signals we might come across. It’s scary to think about this at a societal scale. People could very well be traumatized by these AI images widely going forward.The wrong precedent
SD’s model leaks are a dangerous precedent to set. In a year or two, these models will become inherently more powerful and photo realistic, capable of generating entirely realistic, compromising, NSFW videos, perhaps, just from a photograph of a loved one. Will anyone now just release an AI model regardless of its catastrophic effects since SD did it earlier on?
It goes without saying - there are inherent risks to this stuff!
Speaking to Emad Directly on the EleutherAI Discord
After my controversial tweets, I was pulled into a conversation directly in the “off-topic” channel on the EleutherAI discord with Emad. I’ve already created a whole google slides timeline, sharing relevant tweets and discord screenshots from my conversation with Emad, and I’ve tried my best to stay objective there. But there were some really particularly concerning comments in this conversation on his part.
He didn’t seem particularly concerned with the negative effects of the model on celebrities being harassed and cited working with celebrities through partnerships and the existence of deepfakes as his reasoning:

Even though I believe he funded the model and runs the Stability AI company, he still believes strongly in a personal responsibility view when it comes to the effects of Stable Diffusion on celebrities:

I’m not sure if there was any significant work on bias put in:
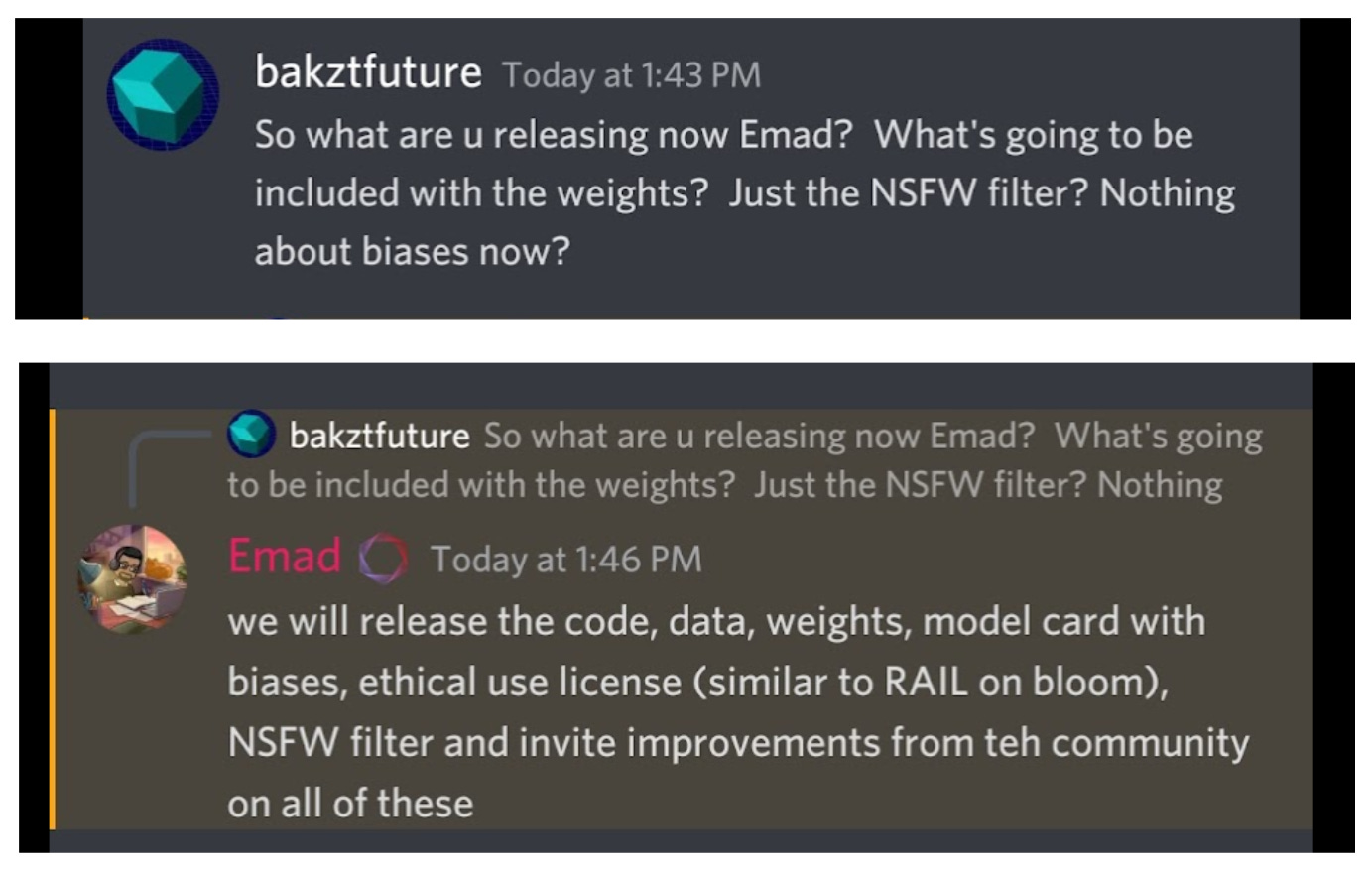

Since the model was leaked, if there were improvements, did they make it in before or after the leak? What were the findings of the community bias/input research?
Although Emad does have a grand vision on releasing the model and allowing open source to build safety/bias tooling on top of it which I think is kind of interesting and potentially a more diverse/inclusive solution:

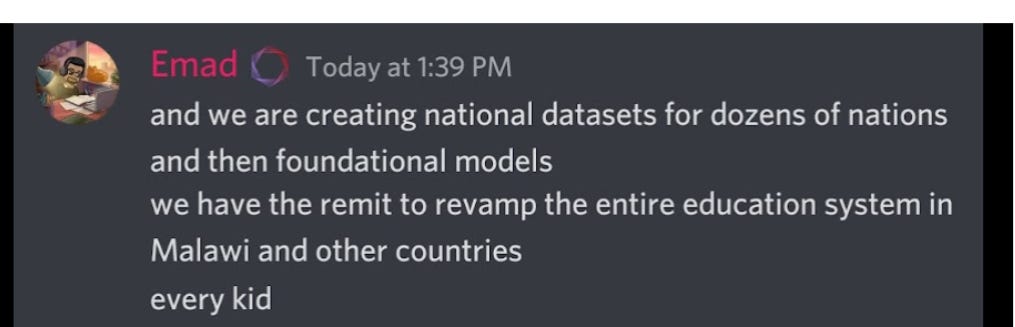
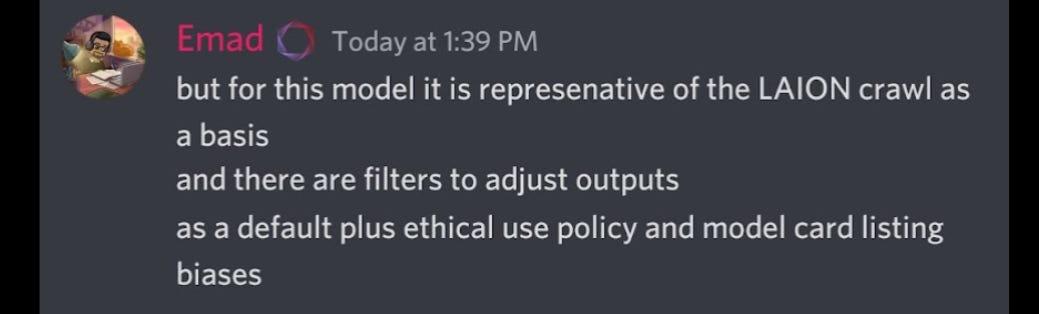

Who’s to say this volunteer/community driven open source tooling will actually keep up with the pace and damage created by the V1 model and future releases? Since the weights have already been leaked, won’t it already be too late?
At times, I took interest in the vision he was proposing. Rather than one company deciding what’s allowed and what isn’t, why can’t we all:

However, when I raised my concern of dealing with the aftermath of this model for years to come he simply responded:

His argument, a utilitarian one, was that most people will be using Stable Diffusion for good, creating art at a level they couldn’t make before, despite its inherent safety risks.
So, I followed up on how he can make this determination, to which he responded:
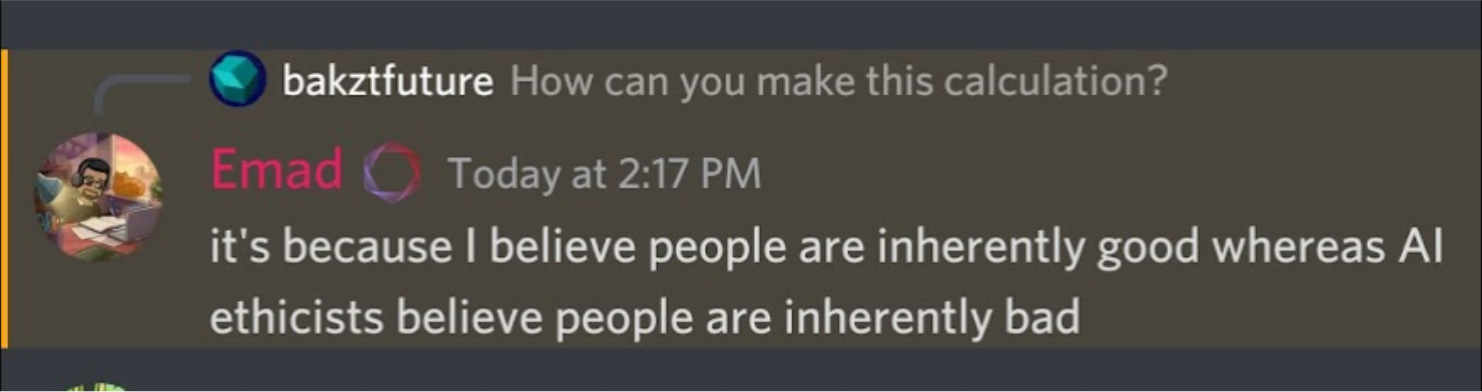
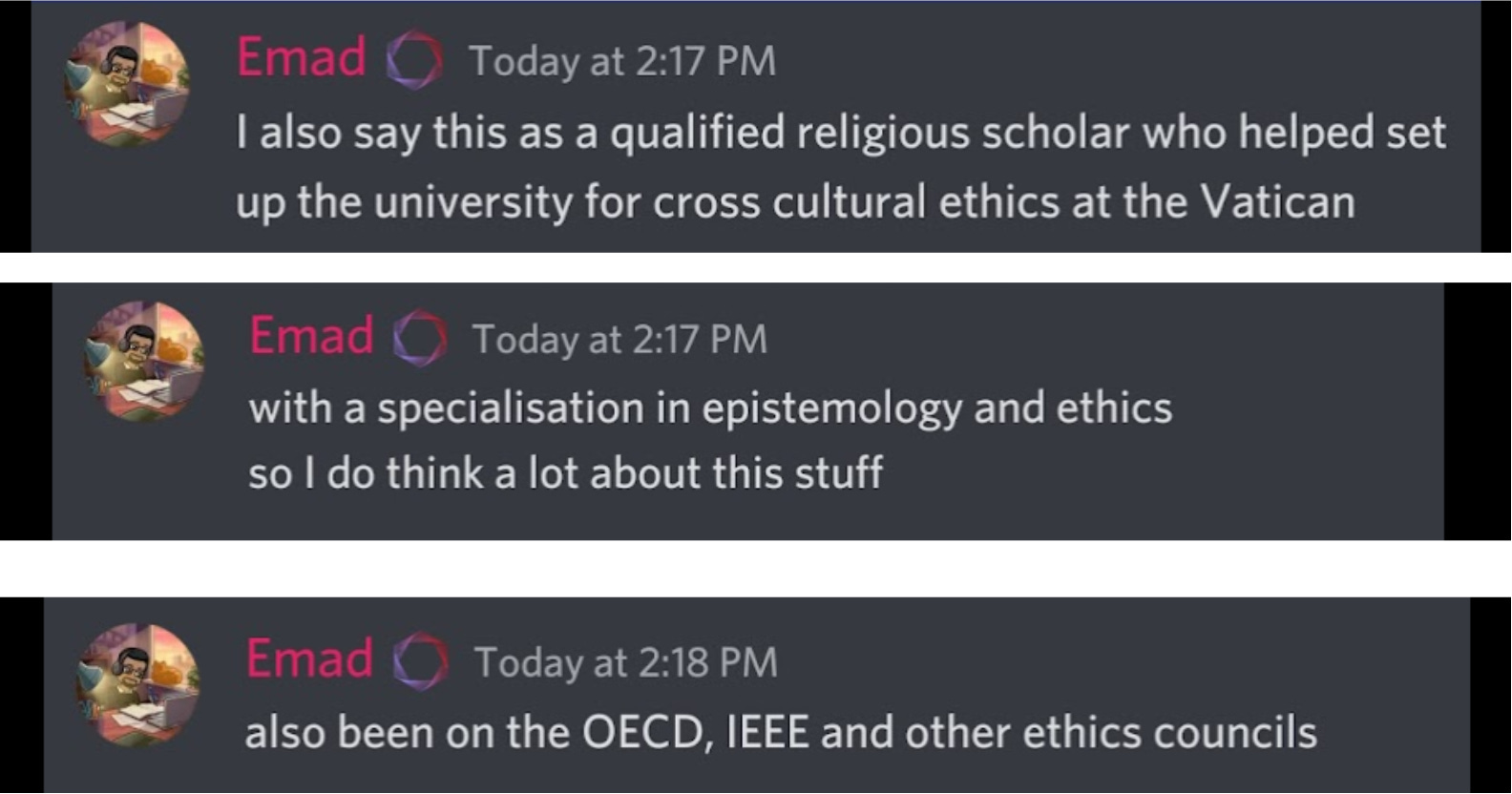
I found his response interesting to say the least.
Eventually, I asked him:

And his response simply was:

To be honest, I was a bit shocked when he said this, but he went on to say that:


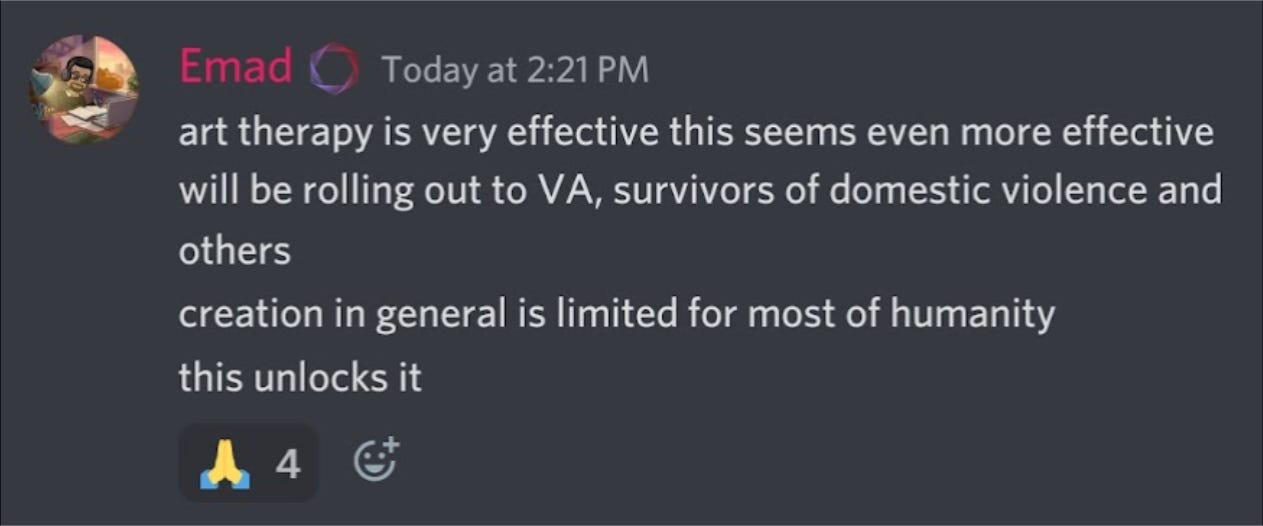
To be fair, Emad then went on the official Stable Diffusion Discord and clarified a lot of the messaging around the public release:

At some point after our discord conversation, I believe I was tagged in a tweet from Emad, along with an OpenAI legal/policy rep where he was asking for help from us (even though I have no affiliation with OpenAI). However, I cannot confirm this as the post was deleted. I wasn’t able to get a screenshot in time.
Since its release, I believe SD has come with a NSFW filter as well as a secret “signature” which can be detected. I’m not sure what other safety/ethics/bias work and controls they put into the model. There might be more, but I’m not sure. Please let me know in the comments down below.
I encourage you to review the raw timeline with screenshots, stable diffusion's public activity/policies, Emad's posts, and more active discussion to draw your own conclusions.
My personal opinion - Don’t Forget Stability AI is a Company!
Personally, I don’t think Emad’s intentions are purely utilitarian. I think it is really interesting that Emad does have commercial intentions through his company - Stability AI. Although I will give them credit for releasing their core model completely to open source, his own company does not tolerate offensive generations themselves - yet, they released a model which is capable of doing so completely uncontrolled at a mass scale. My personal opinion is that he may not necessarily be a true utilitarian. I feel like he’s just more willing to make that scale of a trade off at the expense of everyone else for his company’s market dominance, controversial hype, and financial gain.
My personal opinion - Stable Diffusion Does Benefit Society At Some Level
I don’t want to ignore the utilitarian argument - I do like that anyone can generate pretty meaningful images now thanks to Stable Diffusion. I don’t think it’s fair that only certain individuals, myself included, receive access to the latest models while most of the eager artists are left waiting in the dark. I also can feel the energy and excitement to advance the space forward - I feel in the weeks SD was rolling out the Multimodal AI space has grown and innovated leaps and bounds compared to just a few months ago.
Addressing Major Criticisms
My tweets generated a significant amount of criticisms and misconceptions, so, I want to take some time out to address these narratives:
Fear mongering
I don’t fully understand where this is coming from. I have been an advocate for AI models and AI based creativity from the beginning. My podcast is literally called Multimodal. To be clear, I think my position is very pro-AI based creativity … just a safer one.
Supporting censorship
I do not support censorship and I strongly believe in artistic expression. To go back to my point, I was simply against releasing the model prematurely. I just think it could take some time before the models are safe enough and society to advance and become more accepting of AI images, to cover the full range of artistic expressibility.
Even Midjourney has community volunteer mods who remove content. Not only that, but they make ethical decisions in the best interests for the positivity of their community all the time. Is Midjourney also censoring people? I’ve already established Stable Diffusion has been deleting inappropriate user art for most of their existence in their discord as well - do you feel the same way about them? Or is it only censoring when OpenAI sets up safe usage policies?
I think there’s some underlying heavy-leaning-OpenAI criticism of me here, which I’m going to be addressing later on in more detail. People seriously think by making videos or tweeting about DALL-E 2, that I support censorship (which I do not). However, I could make a similar counter argument here though to such folk - what kinds of negative qualities do you think you are supporting by using, promoting, or defending Stable Diffusion?
"Think of the children" narrative
I think this is a decent narrative - maybe we should be thinking of the children when unleashing an AI model which has the potential to negatively alter public discourse as we know it! We have to look out for kids too - especially those who do not have strong mental health standing, are in vulnerable situations, and who may not have strong family and community support structures.
I actually agree with the other part of this tweet, so, I’ll address this other inherent narrative in the next section. Thanks again to Nathan for sharing this.
More people should have been given access to existing models like DALL-E 2
I think OpenAI has been trying their best to increase access. They recently were trying to scale to 1 million DALL-E 2 users, keeping safety and technical challenges in mind. However, today, I want to call out a specific company. I think Google Brain should have released Imagen and Parti, creating their own Public Betas too. I just don’t understand. What’s the point of Google teasing these models to the AI art community but never releasing them? I also think they have the capacity to handle safety/ethical/legal concerns while also leveraging their talent and compute resources to scale quickly to millions of users.
In the absence of Google Brain, Deepmind, Microsoft, Adobe, Amazon, or any other competitors, I want to say here that in the past few months, I think there was a vacuum created in the AI art space. In the absence of viable alternatives, many, often seedy, AI art communities were formed. If this SD stuff goes south, I feel like all the major players had an indirect role in this too - whether they realize it or not. Even if it was indirect, participation and multiple options could have established consumer choice and created more positive community norms for the whole industry going forward.
You are a clout chaser
I don’t really benefit from heated content like this. I’ve built a following more on the positive, constructive end of the space. Most of my highest performing articles, tweets, and videos were either resources, openly sharing techniques, predictions about the future, heavily optimistic takes, or talking about the real world effects of AI technology. In fact, I even get criticized as more of a “hype” part of the space - not on the hater end of the spectrum. In this case with SD, I’m just trying to voice my opinion, which is one of many, on this matter. That’s it.
You cannot say anything about Open Source, It is Inevitable
I agree with this for the most part. However, in my specific case, I have a platform, and I can voice concerns and hope for improvements. I like to think maybe I did help push SD towards a more positive direction. However, to be fair, it does also look like their team was already working on addressing these types of concerns behind the scenes. Perhaps, pressure from me improved the public messaging and community update frequency around it.
You made a bad initial position and now you are stuck defending it
I change my position all the time! Especially based on new information, industry developments, and different perspectives.
Just last week, I tweeted this:

There might be more nuance here than my original position - but I really do try my best to equally talk about the positives and even the negatives at times.
You are a ride or die DALL-E 2 User
I mean, take a look at the screenshot above - I’ve stated the opposite quite clearly.
I also recommend you check out my last podcast where I openly criticized OpenAI’s DALL-E 2 Credits Pricing model. I think they actually might be upset with me about it (maybe).
Someone would have released something like Stable Diffusion Open Source eventually
This is sort of true. However, I would argue we’ve known multimodal models of this capability have been possible since late 2020 and no one has really released a model like this before. I like to think the safety and ethical concerns prevented others from doing this - it certainly even held Google Brain back from releasing their models. I sometimes think Stable Diffusion may have been the first to set the precedent here in this significant way. I think we had the chance to set positive norms before, but now many of these may be out the door. So, maybe it was inevitable.
Open source wants to be Free, Information wants to be Free
I want to agree with this sentiment. Ideologically, it is true. However, in the real world, there is an establishment. You can get sued. There are societal, legal, financial, cultural, and more dangerous mechanisms available that prevent this ideal from being truly achievable. We’ll see how powerful people react to the potential harassment at scale they may experience from so-called AI art generated with models like Stable Diffusion. Maybe this shouldn’t be the case, but I do think there are limits to this ideology - we’ve sort of already seen this play out. Ask Julian Assange how he’s doing.
You are against Open Source Innovation
No. I think I’m just concerned on a safety/ethical level. That’s all. In fact, I will be releasing my own open source project I’ve been working on this summer soon.
Also, is Stable Diffusion truly innovative? It seems like mostly similar technology which has already been commercially released. This is more about copying existing technology with some architectural/cultural differences. After SD’s release, we may see open source innovation, but this will be at the tooling/UI level not at the model level underpinning this argument now.
You Support The Artist Revolt
While I had made those tweets, simultaneously, Stable Diffusion was being criticized by digital artists for making it easy to mimic their styles, I believe this eventually lead to the removal of one of their community Twitter accounts, allegedly.
My concerns were different from this issue, however, I do sympathize with the artists involved. Unfortunately, I don’t want to get into it here, but my own opinion on this is:
I’m open to revisiting this, but this is my thinking for now.
My Opinions are not representative of the entire space at this point on time
I ran a poll after my tweets to see my audience’s perceptions of the risk of Stable Diffusion:
For the most part, people completely disagreed with me. It’s possible I’m completely wrong here, but like I said, my opinion is one of many.
“You Can Already Do All of this In Photoshop”
Ok, so why don’t you go do that? What’s the point of releasing the model? I’d love to hear your thoughts on this one.
You Don’t Cover Enough Activity in the Open Source Space
I like to think I exclusively covered many of the early Open Source stuff such as DALL-E mini, cogview, and GPT-NeoX. However, since then, there has just been so much activity going on in the open source world for the past couple months, to be honest, I’ve struggled to simply keep up. I don’t have the bandwidth to keep up with so many open source community discord servers. I encourage others to cover this space too, I’m not the only voice here. Also, I do have some safety/ethical apprehensions of my own with some of the projects and their respective Discord community cultures. Finally, my audience is mainly end users/developers of LLM and multimodal AI products, I tend to mainly cover products that I feel are not only safe but commercially, “mainstream ready” for a larger audience with varying levels of experience. This is why I don’t talk a lot about Google Colab notebooks or even projects which require cloning a github repository, for example.
You are taking a “moral high ground”
No. I don’t think so. It’s just an opinion. I’ve tried my best here to share my perspective. Also, I’m not proud either … especially some of my behaviour on Twitter in the past has not been exemplary. Please don’t look at me as a role model in this space.
I have No Relationship with OpenAI
I don’t know how often I have to say this - but I do not have any affiliation nor do I speak on behalf of OpenAI. They are just a focus on my YouTube Channel and other channels because I believe they are a market leader in this space.
I feel it’s really important to correct this narrative and misconception, so, let me be clear. I do not have inside information from OpenAI. I do not collaborate with them in any capacity. In fact, you all should know that for the most part, OpenAI completely ghosts me. Their employees do not get back to me at all and to this day, no OpenAI employee has even been on my podcast despite multiple requests to have them on.
I spoke out on my own about this Stable Diffusion stuff and didn’t even reach out to them about it before making those tweets. They are one of many players in this space.
Finally, I do encourage you all to actually listen to my podcast and watch my work. I’ve often been critical of OpenAI, if anything.
The Hypocrisy of the LLM and Multimodal Industry
What I found most shocking about my original tweet - many of my followers supported my position or offered constructive feedback, but the actual industry, employees, and companies in a position of power didn’t join me in echoing these concerns.
I will always remember this. The same companies that argue their models are too dangerous to release to the world at catastrophic levels were completely silent about the release of such a model, one could argue like Stable Diffusion. These people, especially the ones who work in legal, policy, and corporate governance went to all the right schools, are paid hundreds of thousands of dollars a year, and have multimillion dollar equity positions but didn’t say a thing. It’s possible they may not actually believe in the risks of SD like I did, but I think that for the most part they did understand the underlying risks here.
These people will happily talk to institutes or podcasts about the ethical risks and challenges of AI. They may have their own nuanced takes on ethics and policy, but when it’s actually time to say something or do something before potential mass harm is done they are completely silent.
I understand there might be corporate/PR risks of speaking out. If Google spoke out, maybe they would just add more fuel to the fire or hurt their brand. However, if the risks are as catastrophic as they have always claimed - the time to speak out was weeks ago, when I did!
I make YouTube videos, but perhaps I care more strongly about this situation than the people who are hired to prevent something like this from happening. What are their true interests?
I can’t begin to express my concern for the larger hypocrisy and cowardice from the all of the large players in this space. This may be one of the biggest legal and policy failures of our decade for this space, depending up on how it all plays out … and when it was actually time to speak up they said nothing about it.
The New Era of Multimodality
To close all of this out, I think we’re in a new era of the emerging Multimodal AI industry. I’m still adjusting and processing it myself. For the time being, I believe Stable Diffusion will be ubiquitous and the most widely used Multimodal AI model in the world. I believe we will see new innovations, tools, plugins, and other advancements like never before. We will hear from new voices and see AI images we simply cannot even conceptualize now. However, I guess I’m also saying that I believe this abundance will come with its own safety, ethical, and other costs. Going forward, Recombinant Art may be associated with far more nefarious types of so-called art and creation. This could be used against our industry in the future by legal/corporate, law enforcement, lobbying, and heavy-handed regulatory interests. At the same time, the norms now are unclear, I’m not quite sure what is allowed. What is acceptable or considered unacceptable. I kind of feel like everyone in the space at this point is just looking out for themselves going forward. Perhaps, open source safety controls will catch up - or not. What will happen to public discourse on the internet going forward over the next year or so? Will we regret the release of the Stable Diffusion model 10 years from now?
Finally, I want to say this is the last I have to say on this issue. The weights are already out there and the world has chosen to go in this direction. There is nothing more I can do at this time. To be clear, I have found all of this not only exhausting but in fact, nauseating. Except for major AI announcements, I will be taking a break for a few weeks from YouTube, twitter, and other social media. I hope to come back with a renewed perspective and some new content that is more positive and just gets back to sharing the kind of stuff I enjoy - interesting use cases, techniques, prompt design, and discussions about the future. I started my channel to share my interesting ideas about the world. To the audience, I’m sorry for the negativity coming from my twitter and other channels lately and the absence of content on my end while dealing with all of this.
Thank you for your time and consideration.
Thanks for putting this together. It's much easier than attempting a retrospective on a discord server that's very crowded.
My biggest takeaway is releases like this should be much slower. I also don't know any documentation on a hidden signature of SD (having been loosely involved in the launch), so I'm curious if you find sources on that. Embedding signatures that are permanent in generated images is quite challenging for many reasons.
the question you posed in your "interview" RE suicide is a transparent disgrace
what if someone had worked on stable diffusion and killed themselves because their model was censored? what's your math work out to there?
it's blatantly obvious you were looking to get a hot take to discredit the release and that's a bad look